{kind=link}
Decision trees are among the most widely used and intuitive algorithms in machine learning. Whether you’re working on classification problems (such as spam detection) or regression problems (like predicting house prices), decision trees can be a powerful tool. Their simplicity, interpretability, and efficiency make them a popular choice for both beginners and experienced data scientists.
In this detailed guide, we will explore the concept of decision trees in machine learning, their structure, algorithms, advantages, disadvantages, applications, and more. By the end, you’ll have a solid understanding of how decision trees work and how they can be applied to real-world problems.
What is a Decision Tree in Machine Learning?
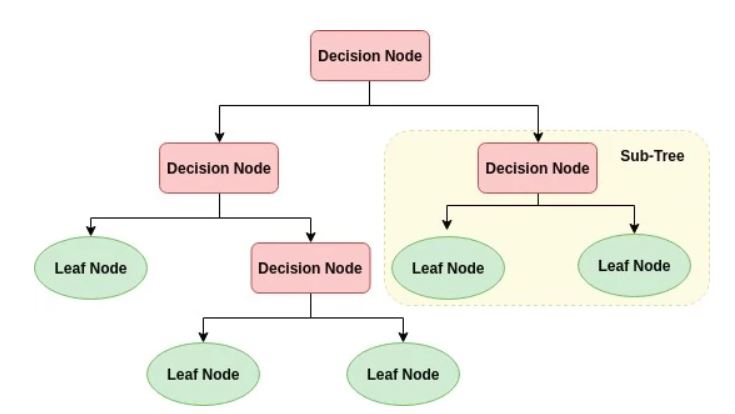
A decision tree is a supervised learning algorithm used for both classification and regression tasks. It resembles a tree-like structure where:
-
Each internal node represents a decision based on an attribute.
-
Each branch represents an outcome of that decision.
-
Each leaf node represents a final decision or classification.
In simple terms, a decision tree breaks down a complex problem into smaller, more manageable parts by asking a series of “yes or no” questions until it reaches a result.
Structure of a Decision Tree
Root Node
-
The topmost node of the tree.
-
Represents the feature that best splits the dataset.
Internal Nodes
-
Represent decisions based on feature values.
-
Connected via branches to other nodes.
Leaf Nodes
-
Represent final outcomes (e.g., classification labels or regression values).
How Do Decision Trees Work?
Decision trees use algorithms to decide how to split the dataset at each step. The splitting criteria depend on measures like information gain or Gini impurity.
Splitting Criteria
-
Entropy and Information Gain
-
Measures the purity of a dataset.
-
Higher information gain means a better split.
-
-
Gini Impurity
-
Measures the probability of incorrectly classifying a randomly chosen element.
-
-
Variance Reduction (for regression)
-
Used to minimize error in predicting continuous values.
-
Types of Decision Trees
Classification Trees
-
Used when the target variable is categorical.
-
Example: Predicting whether an email is spam or not.
Regression Trees
-
Used when the target variable is continuous.
-
Example: Predicting housing prices.
Building a Decision Tree: Step by Step
-
Select the Best Attribute
-
Choose a feature that provides the highest information gain.
-
-
Split the Dataset
-
Divide the dataset based on feature values.
-
-
Repeat Recursively
-
Keep splitting until leaf nodes are reached.
-
-
Stop Criteria
-
Maximum depth reached.
-
Minimum samples per node.
-
No further improvement possible.
-
Decision Tree Algorithms
ID3 (Iterative Dichotomiser 3)
-
Uses entropy and information gain to build the tree.
C4.5
-
Successor to ID3.
-
Handles both categorical and continuous attributes.
CART (Classification and Regression Tree)
-
Uses Gini index for classification and mean squared error for regression.
Advantages of Decision Trees
-
Easy to understand and interpret: Visual representation is intuitive.
-
No need for feature scaling: Works well without normalization.
-
Handles both numerical and categorical data.
-
Non-parametric: Does not assume any prior distribution.
Disadvantages of Decision Trees
-
Overfitting: Trees can become too complex.
-
Unstable: Small changes in data may result in a different tree.
-
Biased towards features with more levels.
How to Prevent Overfitting in Decision Trees
Pruning
-
Reduces the size of the tree by removing nodes that add little predictive power.
Setting Maximum Depth
-
Restricts how deep the tree can grow.
Minimum Samples Split
-
Requires a minimum number of samples to split a node.
Decision Trees vs. Other Algorithms
Decision Trees vs. Random Forest
-
Random Forest is an ensemble of decision trees.
-
Reduces overfitting by averaging predictions.
Decision Trees vs. Logistic Regression
-
Logistic regression is better for linear problems.
-
Decision trees handle non-linear relationships well.
Real-World Applications of Decision Trees
Healthcare
-
Diagnosing diseases based on symptoms.
Finance
-
Predicting loan default risks.
Marketing
-
Customer segmentation for targeted campaigns.
Manufacturing
-
Quality control and fault detection.
Education
-
Predicting student performance.
Implementing a Decision Tree in Python
Step 1: Import Libraries
Step 2: Load Dataset
Step 3: Train the Model
Step 4: Visualize the Tree
Best Practices for Using Decision Trees
-
Use cross-validation to evaluate performance.
-
Prune trees to prevent overfitting.
-
Combine with ensemble methods (Random Forest, Gradient Boosting).
-
Balance datasets to avoid bias.
Future of Decision Trees in Machine Learning
Decision trees continue to play a vital role in machine learning. With improvements like XGBoost, LightGBM, and CatBoost, they form the backbone of many advanced AI systems. Their interpretability ensures they remain a go-to tool in explainable AI (XAI).
Conclusion
Decision trees are a powerful and intuitive machine learning algorithm used for both classification and regression tasks. While they have some drawbacks, their interpretability and wide range of applications make them indispensable in the data science toolkit. By combining decision trees with ensemble methods, we can overcome their limitations and build highly accurate predictive models.
Whether you are a beginner learning machine learning or an advanced practitioner, mastering decision trees is essential to understanding the foundations of AI and predictive analytics.