{kind=link}
11
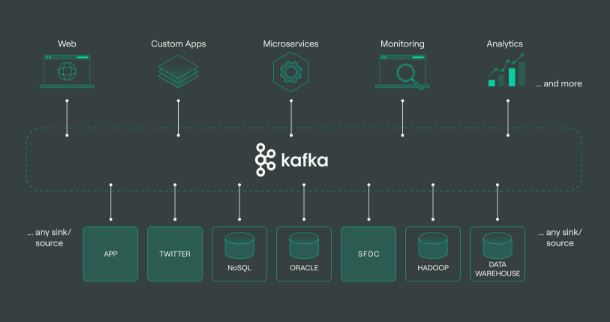
Apache Kafka is a powerful open source distributed streaming platform used for building real-time data pipelines and applications. It acts like a central nervous system for a company’s data, allowing different systems to reliably send and receive massive amounts of information in real-time.
Analogy: A Super-Fast, Organized Postal Service 📮
Imagine a massive, incredibly fast, and organized postal service for data.
- Producers (like a website’s user activity tracker) are like people writing letters (data messages).
- They send these letters to specific Topics (like dedicated, labeled mailboxes for “User Clicks” or “New Signups”).
- Consumers (like an analytics dashboard or a database) can subscribe to any of these topics. They receive a copy of every letter as soon as it arrives, in the exact order it was sent.
Kafka is the post office that manages all these mailboxes, ensuring no letters are lost and that delivery is nearly instantaneous.
How Does Kafka Actually Work?
Kafka is built around a few core concepts:
- Producers: Any application that sends or “publishes” a stream of records to a Kafka topic.
- Consumers: Any application that “subscribes” to a topic to read and process the stream of records.
- Topics: A category or feed name to which records are published. Topics are split into partitions, which allow the data to be spread across multiple servers for scalability.
- Brokers: The Kafka servers that form the cluster. They store the data durably and manage the topics and partitions.
Because Kafka is distributed, it runs on a cluster of these brokers. This makes it highly scalable and fault-tolerant; if one server fails, the data is safe on other servers.
Why is Kafka So Popular?
- High Throughput: It can handle hundreds of thousands or even millions of messages per second.
- Scalability: You can seamlessly add more brokers to the cluster to handle growing data volumes.
- Durability and Reliability: Messages are written to disk and replicated across the cluster, which prevents data loss.
- Decoupling of Systems: Producers don’t need to know anything about the consumers, and vice versa. They only need to know about Kafka. This makes the entire system architecture more flexible and resilient.
Real-World Use Cases
- Real-time Analytics: Powering the live dashboards that show Uber cars on a map or track Netflix viewing statistics.
- Website Activity Tracking: Capturing every user click, search, and interaction on a high-traffic website in real-time.
- Log Aggregation: Collecting and centralizing log files from hundreds of different servers for monitoring and analysis.