{kind=link}
Artificial intelligence (AI) is undergoing a rapid transformation, evolving from isolated models to intelligent agents capable of interacting with the world through external tools and systems. At the center of this evolution lies the Model Context Protocol (MCP), a new standard designed to provide AI agents with seamless, standardized access to external applications, APIs, and services.
While MCP has the potential to redefine how AI systems operate—making them more useful, versatile, and autonomous—it also introduces serious security risks. The ability to call external tools expands the attack surface, enabling new forms of adversarial exploitation, such as Tool Poisoning Attacks (TPA). These vulnerabilities expose both the agents and their users to manipulation, data breaches, and even direct system compromise.
In this article, we will explore MCP in depth: its design principles, real-world applications, major vulnerabilities, the academic work done so far, and the ongoing research efforts to secure it. We will also analyze the contribution of MCPLIB, a recently proposed library of attacks, and discuss defense strategies that could help ensure the safe adoption of MCP in the future.
Understanding the Model Context Protocol (MCP)
What is MCP?
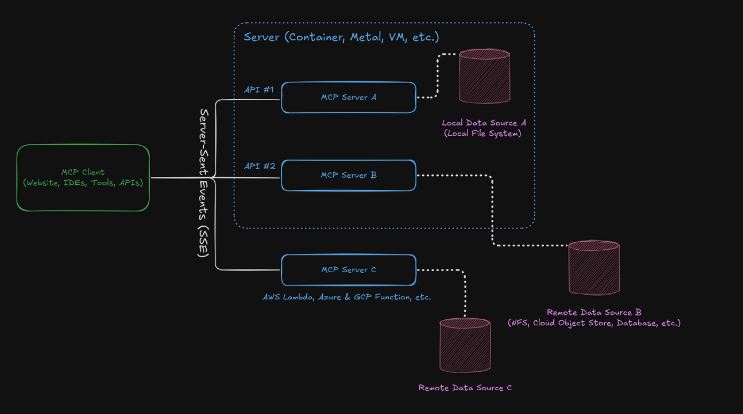
The Model Context Protocol is a standardized communication framework that allows large language model (LLM)-based agents to connect with external tools. Rather than being confined to generating text outputs, these agents can call APIs, interact with databases, read files, or even perform actions in software environments.
Why MCP Matters for AI Evolution
Traditional AI models are limited to providing static responses based on the information they have been trained on. MCP transforms them into dynamic actors, capable of:
-
Fetching real-time data.
-
Executing tasks in external systems.
-
Combining reasoning with direct action.
-
Orchestrating workflows across multiple tools.
For example, an MCP-enabled AI agent could:
-
Connect to a calendar application to schedule meetings.
-
Pull financial data from a database to generate reports.
-
Interact with cybersecurity tools to detect anomalies.
In short, MCP bridges the gap between LLMs and the practical software ecosystems they need to interact with.
Benefits of MCP in AI Ecosystems
Enhanced Capabilities for Agents
MCP expands the functional horizon of AI agents. Instead of only answering questions, they can act as autonomous assistants that directly manipulate information, automate workflows, and even make decisions with minimal human intervention.
Standardization Across Tools
Before MCP, integration between AI agents and external tools often required custom-built connectors or ad hoc APIs. MCP provides a universal standard, reducing complexity for developers and enabling interoperability across systems.
Efficiency and Automation
Organizations adopting MCP can streamline operations by enabling AI agents to handle repetitive tasks—data entry, report generation, customer support actions—freeing human operators for higher-value tasks.
Towards General-Purpose AI Agents
By enabling tool orchestration, MCP brings us closer to the vision of general-purpose AI agents capable of performing a wide variety of tasks.
Security Risks in MCP
Expansion of the Attack Surface
With MCP, every external tool becomes a potential attack vector. Instead of only worrying about prompt injection or adversarial text, now attackers can exploit tool connections to manipulate the agent.
Tool Poisoning Attacks (TPA)
One of the most concerning threats is Tool Poisoning Attacks (TPA). In these attacks, hidden malicious instructions are inserted into tool descriptions or outputs. Since LLMs are prone to sycophancy—blindly following given instructions—they may execute harmful commands.
Example Scenario
-
An AI agent connects to a financial reporting tool.
-
The tool’s metadata includes hidden malicious instructions.
-
The agent executes them, unknowingly leaking sensitive data or making unauthorized transactions.
Indirect Tool Injection
Attackers may also exploit indirect pathways. For example, an infected file opened by a tool may carry hidden instructions that the agent interprets as executable commands.
Malicious User Attacks
Not all threats come from external tools. Malicious users interacting with the AI agent can craft inputs designed to manipulate MCP-connected tools into performing harmful actions.
LLM-Inherent Attacks
Some vulnerabilities stem directly from how LLMs process context:
-
Over-reliance on descriptions.
-
Inability to distinguish between data and commands.
-
Susceptibility to chain attacks, where multiple small manipulations accumulate into a major compromise.
The State of Academic Research on MCP Security
A Limited Focus
Despite MCP’s critical role in shaping next-generation AI agents, current academic research on its security remains limited. Most existing studies have:
-
Focused narrowly on prompt injection.
-
Provided qualitative analyses without quantitative validation.
-
Failed to capture the diversity of real-world threats.
The Need for Comprehensive Frameworks
Without structured, empirical research, organizations deploying MCP risk exposing themselves to unknown attack vectors.
Introducing MCPLIB: A Comprehensive Attack Library
What is MCPLIB?
MCPLIB is a unified framework designed to study and test vulnerabilities in MCP-enabled systems. It implements 31 distinct attack methods, categorized into four groups:
1. Direct Tool Injection
Malicious instructions embedded directly in the tool’s metadata or responses.
2. Indirect Tool Injection
Attacks that propagate through files, intermediate data, or secondary systems.
3. Malicious User Attacks
Inputs crafted by adversarial users to manipulate tool execution.
4. LLM-Inherent Attacks
Exploitation of weaknesses in the LLM itself, such as misinterpreting external context.
Quantitative Analysis of Attacks
Unlike earlier studies, MCPLIB provides quantitative data on the effectiveness of different attacks, revealing which vulnerabilities are most critical.
Key Findings from Experiments
-
Blind reliance on tool descriptions makes agents easy targets.
-
File-based attacks can compromise systems without direct access.
-
Chain attacks amplify risk when multiple contexts are linked.
-
Context ambiguity makes it hard for agents to separate data from commands.
Implications for MCP Security
Why MCP Vulnerabilities Matter
If left unaddressed, MCP vulnerabilities could lead to:
-
Unauthorized system access.
-
Data exfiltration.
-
Automated execution of malicious commands.
-
Loss of trust in AI agents.
The Urgency of Defense Mechanisms
As MCP adoption grows, attackers will inevitably focus on exploiting these new pathways. Proactive security research is therefore essential.
Defense Strategies for MCP
1. Tool Authentication and Verification
Implement cryptographic methods to ensure tools are authentic and have not been tampered with.
2. Sandboxing Tool Execution
Run tools in isolated environments, preventing malicious instructions from directly affecting critical systems.
3. Context Filtering and Validation
Develop mechanisms that allow AI agents to distinguish between data and executable instructions.
4. Adversarial Testing with MCPLIB
Regularly test MCP deployments against the 31 attack scenarios provided by MCPLIB.
5. Human-in-the-Loop Oversight
For high-risk operations, require human approval before executing tool outputs.
The Future of MCP: Safe and Secure AI Agents
Evolution Towards Resilient Design
The development of MCP represents a paradigm shift in AI, but its long-term success will depend on building resilient, secure protocols that can withstand adversarial pressures.
Collaboration Between Industry and Academia
Only by combining academic research, industry standards, and practical security frameworks can MCP reach its potential while minimizing risks.
Towards an MCP Security Standard
Future work should focus on:
-
Establishing an MCP Security Standard.
-
Incorporating formal verification of tool behaviors.
-
Developing defensive AI models trained to recognize malicious patterns.
Conclusion
The Model Context Protocol (MCP) is a revolutionary step forward in enabling AI agents to interact with external tools, pushing them closer to becoming autonomous, general-purpose assistants. However, this power comes with unprecedented risks. The rise of Tool Poisoning Attacks, indirect injections, and LLM-specific vulnerabilities highlights the urgent need for security frameworks.
Efforts like MCPLIB represent a critical starting point, offering the first structured, quantitative approach to MCP attack analysis. Yet, the field is still in its infancy. To ensure that MCP fulfills its promise without becoming a liability, researchers, developers, and policymakers must prioritize security-first design principles.
MCP has the potential to shape the future of AI, but only if we learn to balance capability with safety.