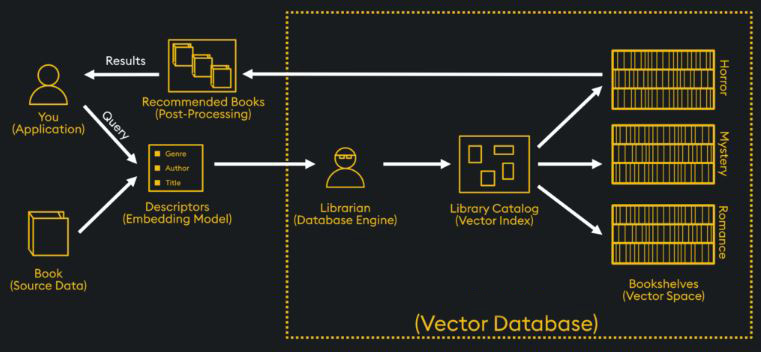
A vector database is a specialized database designed to store and search for data based on its meaning and context, rather than exact keywords. Large Language Models (LLMs) need them to have a long-term memory for custom data, which is the foundation of modern AI applications like Retrieval-Augmented Generation (RAG).
First, What is a Vector Embedding? (A Number for Meaning) 🔢
To understand vector databases, you must first understand vector embeddings. An embedding is a long list of numbers (a vector) that represents the “meaning” of a piece of data.
An AI model is trained to convert text, images, or audio into these numerical representations. The key is that items with similar meanings will have similar lists of numbers.
Analogy: A Coordinate System for Ideas 🗺️ Think of it like a giant map where every concept has coordinates. The vectors for “king” and “queen” would be very close to each other. The vector for “car” would be very far away from them, but close to the vector for “truck.”
So, What is a Vector Database?
A vector database is a system that is highly optimized for one specific job: finding the “nearest neighbors” to a query vector, incredibly fast. You give it a vector, and it searches through millions or billions of other vectors to return the ones that are mathematically closest (most similar) to your query.
Why Do LLMs Need This? (The Memory Problem) 🧠
LLMs like GPT-4 are incredibly powerful, but they have two major limitations:
- Knowledge Cutoff: They only know about information from their training data, which becomes outdated.
- Limited Context Window: They can only “remember” a few thousand words of a single conversation at a time. They have no memory of your company’s private documents or past conversations.
The Solution: Retrieval-Augmented Generation (RAG)
Vector databases solve this memory problem. This process is called Retrieval-Augmented Generation (RAG).
How RAG Works:
- Store: You take your private documents (e.g., company reports, support tickets), break them into chunks, convert each chunk into a vector embedding, and store them in a vector database.
- Query: When a user asks a question (e.g., “What were our sales in Q2?”), your application converts this question into a vector embedding.
- Retrieve: The application uses this question vector to search the vector database, which instantly finds the most relevant document chunks (e.g., the parts of the Q2 sales report).
- Augment & Generate: The application then sends a new prompt to the LLM that includes both the original question AND the relevant chunks retrieved from the database. The LLM then generates an answer based on the specific information it was just given.
This process gives the LLM access to a massive, long-term memory that is specific to your data, allowing it to answer questions accurately without needing to be retrained.